I’ve decided to explore what happens when a ZVM (Zerto Virtual Manager) in either the protected site or the recovery site is down for a period of time, and what happens when it is back in service, and most importantly, how an outage of either ZVM affects replication, journal history, and the ability to recover a workload.
Before getting in to it, I have to admit that I was happy to see how resilient the platform is through this test, and how the ability to self-heal is a built in “feature” that rarely gets talked about.
Questions:
- Does ZVR still replicate when a ZVM goes down?
- How does a ZVM being down affect checkpoint creation?
- What can be recovered while the ZVM is down?
- What happens when the ZVM is returned to service?
- What happens if the ZVM is down longer than the configured Journal History setting?
Acronym Decoder & Explanations
| ZVM | Zerto Virtual Manager |
| ZVR | Zerto Virtual Replication |
| VRA | Virtual Replication Appliance |
| VPG | Virtual Protection Group |
| RPO | Recovery Point Objective |
| RTO | Recovery Time Objective |
| BCDR | Business Continuity/Disaster Recovery |
| CSP | Cloud Service Provider |
| FOT | Failover Test |
| FOL | Failover Live |
Does ZVR still replicate when a ZVM goes down?
The quick answer is yes. Once a VPG is created, the VRAs handle all replication. The ZVM takes care of inserting and tracking checkpoints in the journal, as well as automation and orchestration of Virtual Protection Groups (VPGs), whether it be for DR, workload mobility, or cloud adoption.
In the protected site, I took the ZVM down for over an hour via power-off to simulate a failure. Prior to that, I made note of the last checkpoint created. As the ZVM went down, within a few seconds, the protected site dashboard reported RPO as 0 (zero), VPG health went red, and I received an alert stating “The Zerto Virtual Manager is not connected to site Prod_Site…”

Great, so the protected site ZVM is down now and the recovery site ZVM noticed. The next step for me was to verify that despite the ZVM being down, the VRA continued to replicate my workload. To prove this, I opened the file server and copied the fonts folder (C:\Windows\Fonts) to C:\Temp (total size of data ~500MB).
As the copy completed, I then opened the performance tab of the sending VRA and went straight to see if the network transmit rate went up, indicating data being sent:
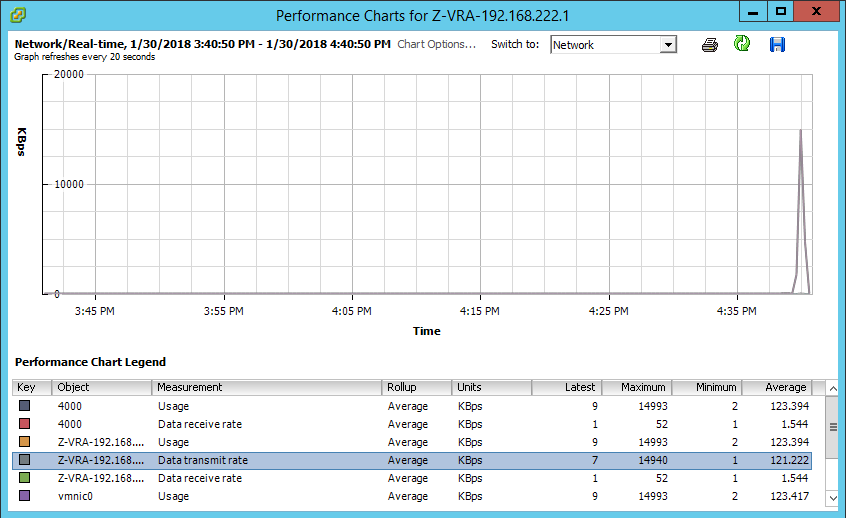
Following that, I opened the performance monitor on the receiving VRA and looked at two stats: Data receive rate, and Disk write rate, both indicating activity at the same timeframe as the sending VRA stats above:
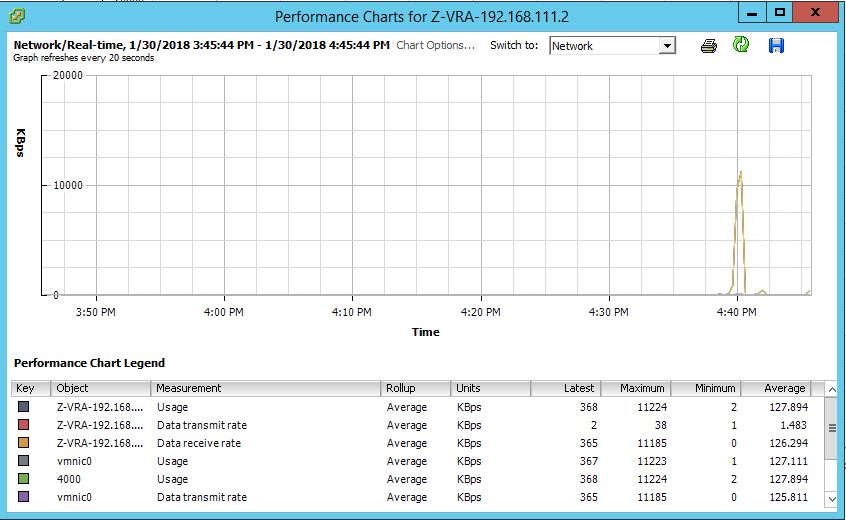
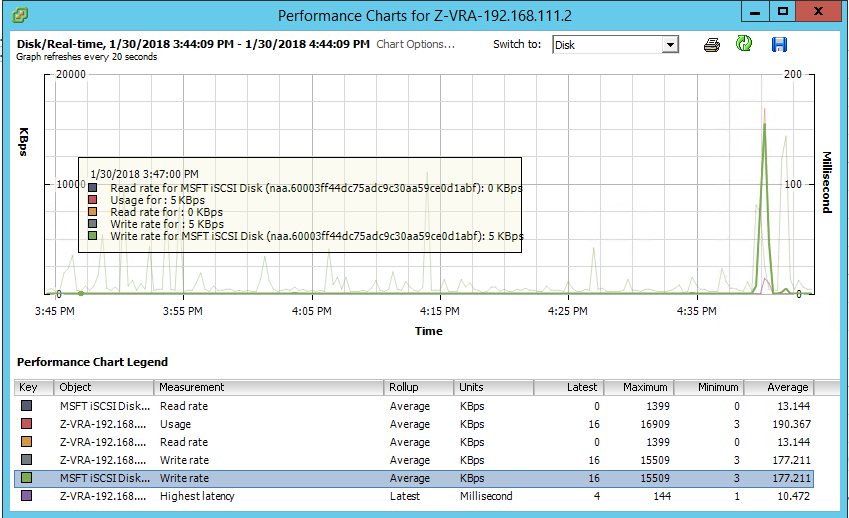
As you can see, despite the ZVM being down, replication continues, with caveats though, that you need to be aware of:
- No new checkpoints are being created in the journal
- Existing checkpoints up to the last one created are all still recoverable, meaning you can still recover VMs (VPGs), Sites, or files.
Even if replication is still taking place, you will only be able to recover to the latest (last recorded checkpoint) before the ZVM went down. When the ZVM returns, checkpoints are once again created, however, you will not see checkpoints created for the entire time that ZVM was unavailable. In my testing, the same was true for if the recovery site ZVM went down while the protected site ZVM was still up.
How does the ZVM being down affect checkpoint creation?
If I take a look at the Journal history for the target workload (file server), I can see that since the ZVM went away, no new checkpoints have been created. So, while replication continues on, no new checkpoints are tracked due to the ZVM being down, since one of it’s jobs is to track checkpoints.
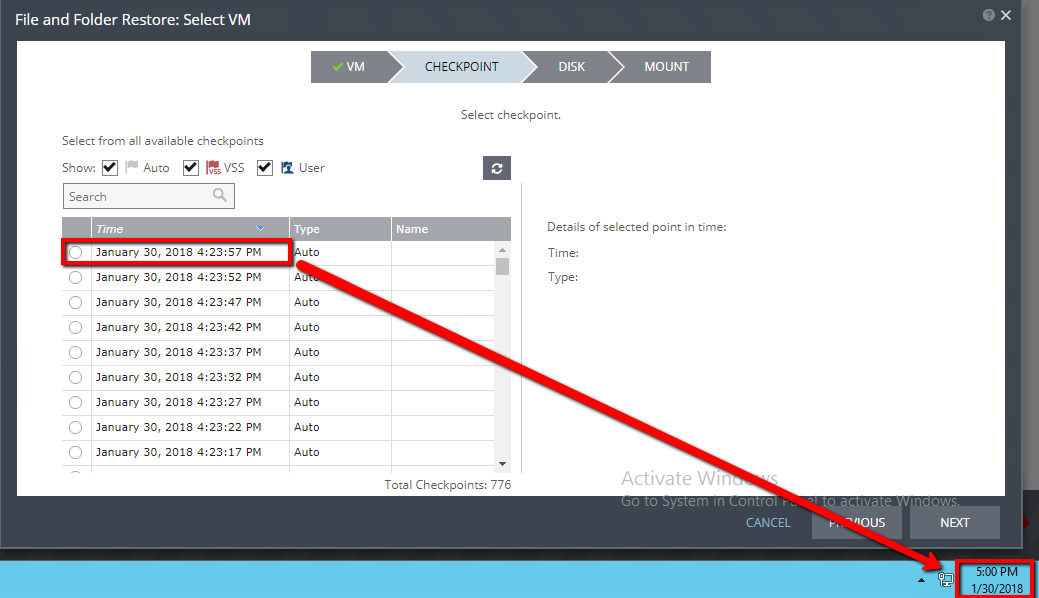
What can be recovered while the ZVM is down?
Despite no new checkpoints being created – FOT or FOL – VPG Clone, Move, and File Restore services are still available for the existing journal checkpoints. Given this was something I’ve never tested before, this was really impressive.
One thing to keep in mind though is that this will all depend on how long your Journal history is configured for, and how long that ZVM is down. I provide more information about this specific topic further down in this article.
What happens when the ZVM is returned to service?
So now that I’ve shown what is going on when the ZVM is down, let’s see what happens when it is back in service. To do this, I just need to power it back up, and allow the services to start, then see what is reported in the ZVM UI on either site.
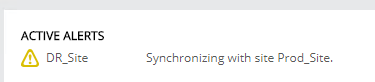
As soon as all services were back up on the protected site ZVM, the recovery site ZVM alerted that a Synchronization with site Prod_Site was initiated:
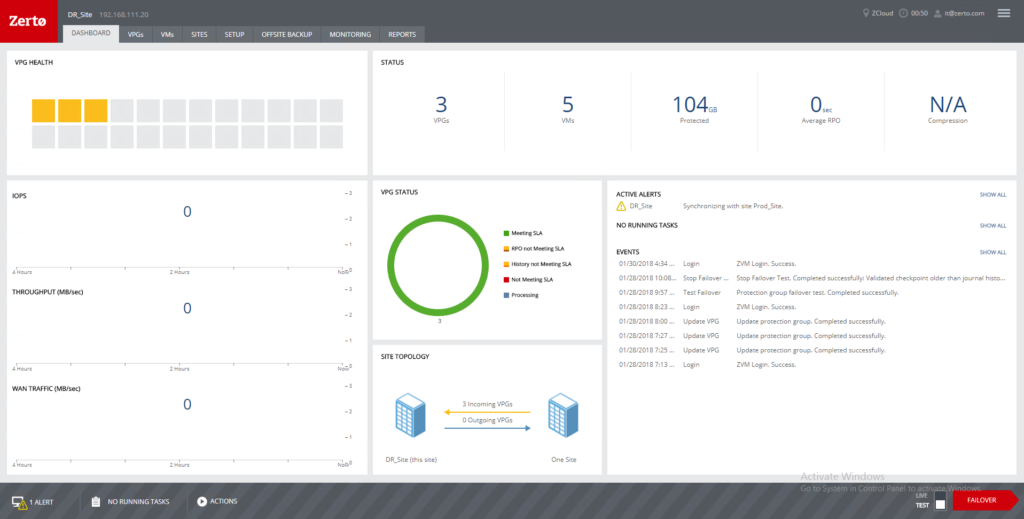
The next step here is to see what our checkpoint history looks like. Taking a look at the image below, we can see when the ZVM went down, and that there is a noticeable gap in checkpoints, however, as soon as the ZVM was back in service, checkpoint creation resumed, with only the time during the outage being unavailable.
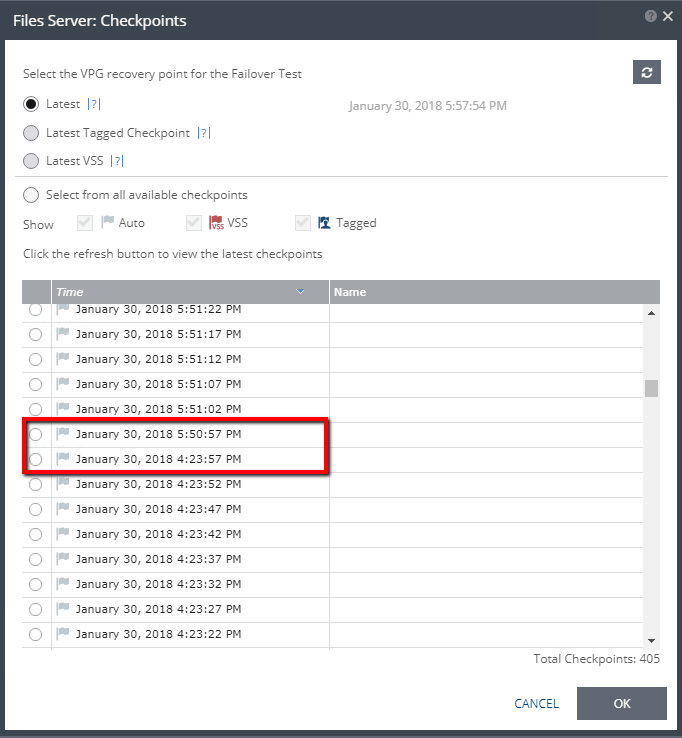
What happens if the ZVM is down longer than the configured Journal History setting?
In my lab, for the above testing, I set the VPG history to 1 hour. That said, if you take a look at the last screen shot, older checkpoints are still available (showing 405 checkpoints). When I first tried to run a failover test after this experiment, I was presented with checkpoints that go beyond an hour. When I selected the oldest checkpoint in the list, a failover test would not start, even if the “Next” button in the FOT wizard did not gray out. What this has lead me to believe is that it may take a minute or two for the journal to be cleaned up.
Because I was not able to move forward with a failover test (FOT), I went back in to select another checkpoint, and this time, the older checkpoints were gone (from over an hour ago). Selecting the oldest checkpoint at this time, allowed me to run a successful FOT because it was within range of the journal history setting. Lesson learned here – note to self: give Zerto a minute to figure things out, you just disconnected the brain from the spine!
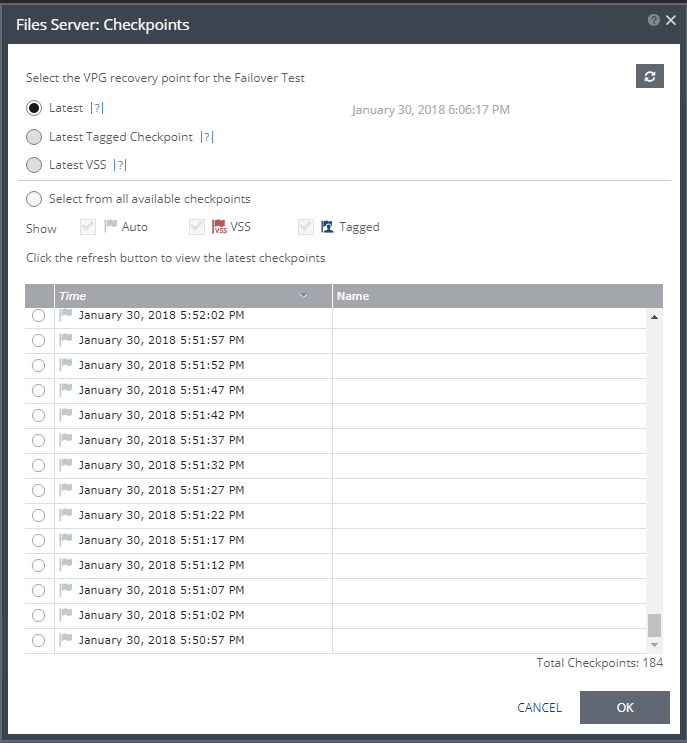
Running a failover test to validate successful usage of checkpoints after ZVM outage:
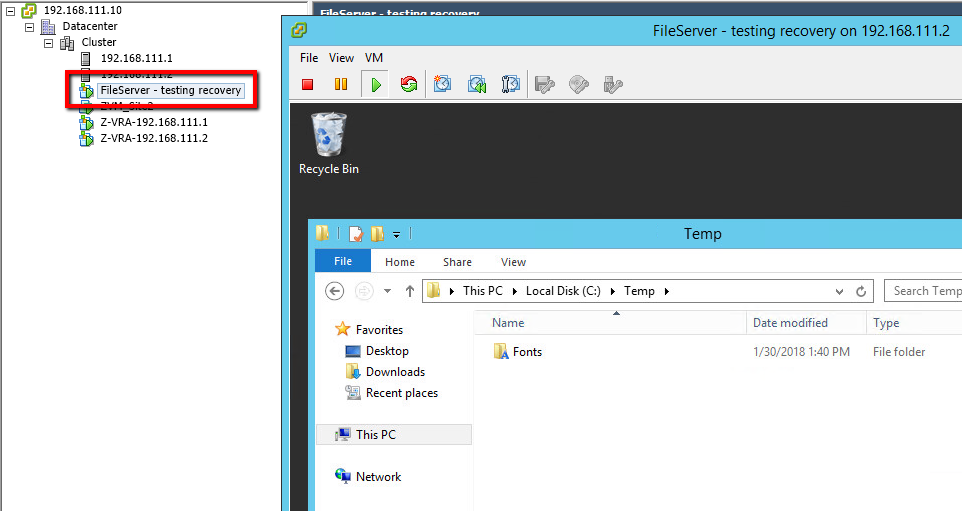
And… a recovery report to prove it:
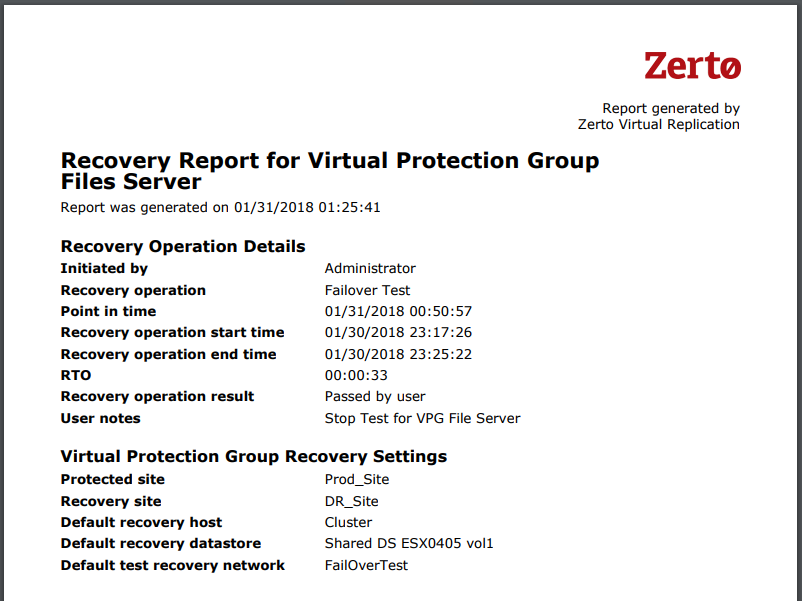
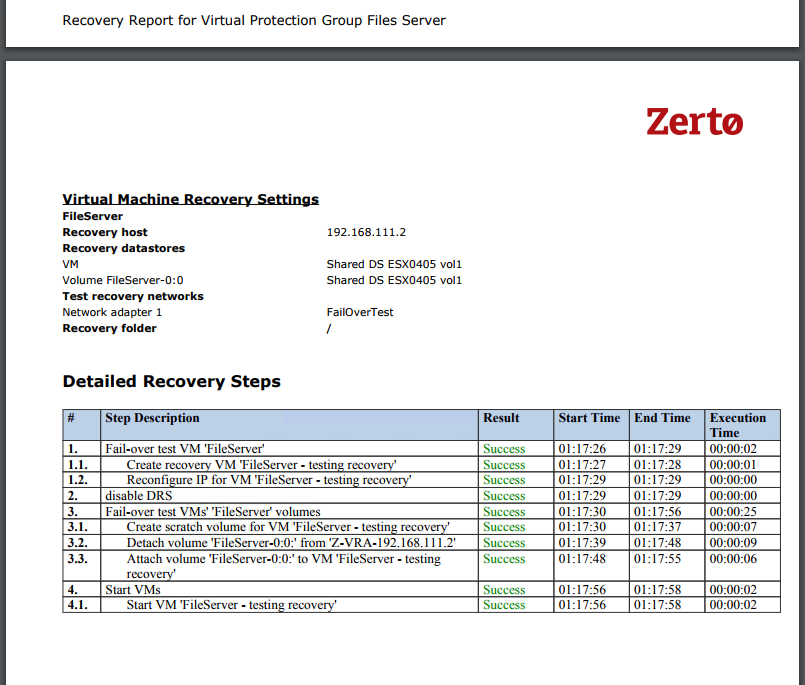
Summary and Next Steps
So in summary, Zerto is self-healing and can recover from a ZVM being down for a period of time. That said, there are some things to watch out for, which include known what your configured journal setting is, and how a ZVM being down longer than the configured history setting affects your ability to recover.
You can still recover, however, you will start losing older checkpoints as time goes on while the ZVM is down. This is because of the first-in-first-out (FIFO) nature of how the journal works. You will still have the replica disks and journal checkpoints committing to it as time goes on, so losing history doesn’t mean you’re lost, you will just end up breaching your SLA for history, which will re-build over time as soon as the ZVM is back up.
As a best practice, it is recommended you have a ZVM in each of your protected sites, and in each of your recovery sites for full resilience. Because after all, if you lose one of the ZVMs, you will need at least either the protected or recovery site ZVM available to perform a recovery. The case is different if you have a single ZVM. If you must have a single ZVM, put it into the recovery site, and not on the protected site, because chances are, your protected site is what you’re accounting for going down in any planned or unplanned event. It makes most sense to have the single ZVM in the recovery site.
In the next article, I’ll be exploring this very example of a single ZVM and how that going down affects your resiliency. I’ll also be testing some ways to potentially protect that single ZVM in the event it is lost.
Thanks for reading! Please comment and share, because I’d like to hear your thoughts, and am also interested in hearing how other solutions handle similar outages.
One thought to “Zerto Virtual Manager Outage, Replication, and Self-Healing”